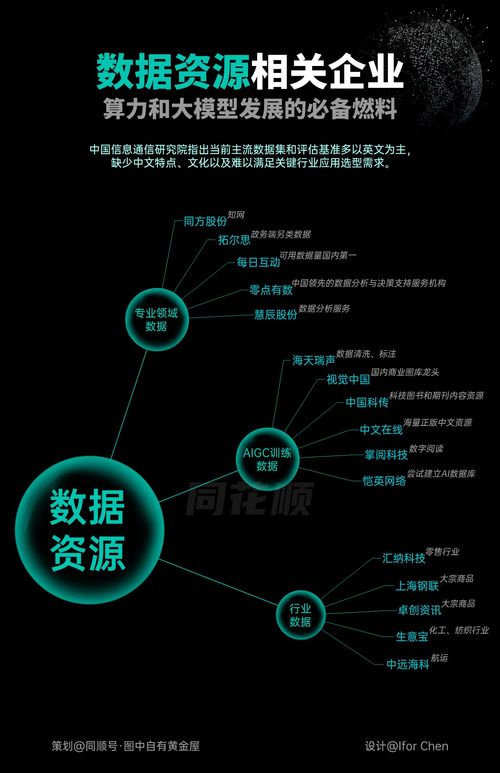
数据资源 大模型发展的必备燃料——从浙江软件开发实践看未来趋势
随着人工智能技术的飞速发展,大模型已成为推动产业变革的核心驱动力之一。而在大模型的训练与应用过程中,数据资源扮演着“燃料”般的核心角色。浙江作为我国数字经济发展的先行区,其软件开发产业在大模型与数据资源的融合创新上,展现出独特的实践路径与发展潜力。
一、数据资源:大模型训练的基石
大模型的训练依赖于海量、高质量、多样化的数据。无论是自然语言处理、图像识别还是多模态交互,模型的表现能力与泛化水平都直接受限于训练数据的规模与质量。数据不仅是模型学习的“原材料”,更是其迭代优化、适应复杂场景的关键支撑。可以说,没有充足、有效的数据供给,大模型的“智能”就无从谈起。
二、浙江软件开发:数据驱动创新的实践场
浙江软件开发产业长期深耕于电子商务、智慧城市、工业互联网、金融科技等领域,积累了丰富的数据资源与应用场景。在推进大模型落地过程中,浙江企业注重将行业数据与模型能力相结合,形成了一系列特色应用:
- 电商与消费领域:利用用户行为数据、商品信息与交易记录,训练推荐系统与客服模型,提升个性化体验与服务效率。
- 智能制造与供应链:通过工业数据优化生产调度、质量检测与物流规划,推动模型在产业端的深度赋能。
- 政务与公共服务:基于政务数据与社会信息,开发智慧审批、城市治理、舆情分析等模型应用,提升治理效能。
这些实践不仅验证了数据资源在大模型落地中的关键作用,也为数据采集、标注、治理与合规使用提供了宝贵经验。
三、挑战与机遇:构建良性数据生态
尽管数据资源的价值日益凸显,但在大模型发展过程中仍面临诸多挑战:数据质量参差不齐、隐私与安全保护要求严格、跨领域数据融合难度大、数据标注成本高昂等。对此,浙江软件开发行业正在积极探索解决方案:
- 加强数据治理与标准化:建立企业级数据中台,推动数据清洗、标注与分类的规范化。
- 创新数据协作模式:通过隐私计算、联邦学习等技术,在保障安全的前提下促进数据共享与价值释放。
- 深化场景驱动:以实际业务需求为导向,提升数据的场景适配性与模型的可解释性。
四、未来展望:从“数据燃料”到“智能引擎”
随着技术的不断演进,数据资源与大模型之间的关系将更加紧密。浙江软件开发产业有望在以下方向持续突破:
- 高质量数据集建设:围绕重点行业构建开放、合规、多样化的数据集,降低模型训练门槛。
- 实时数据与流式计算:结合边缘计算与物联网,实现数据实时采集与模型动态优化。
- 人机协同的数据标注:利用AI辅助标注工具,提升数据生产效率与一致性。
- 合规与伦理框架:建立适应大模型发展的数据使用规范,平衡创新与安全。
数据资源如同大模型发展的“燃料”,其规模、质量与利用效率直接决定了模型能力的上限。浙江软件开发产业凭借其丰富的应用场景与数据积累,正在积极探索数据驱动下的模型创新路径。只有构建起健康、可持续的数据生态,才能真正释放大模型的潜力,推动人工智能技术更好地赋能经济社会发展。
如若转载,请注明出处:http://www.zjgswlwkjyxgs.com/product/46.html
更新时间:2026-06-19 16:45:06